Оптимизация фильтров в интернет-магазине


В данной статье хотелось бы разобраться с такой серьёзной проблемой, как фильтры каталога в интернет-магазинах.
На сайте каждого хорошего интернет-магазина есть блок с фильтрацией, при помощи которого пользователи могут найти интересующий их товар достаточно быстро.
Типичный пример фильтров на интернет-магазине Allo.ua:

Но фильтры также могут нанести существенный ущерб ранжированию и индексации сайта в поисковых системах. К сожалению, никто об этом не задумывается на этапе создания интернет-магазина, а стоило бы, так как внедрение минимального SEO-friendly избавит сайт от технических проблем с индексацией и ранжированием ресурса в поисковых системах.
Попробуем разобраться, какие проблемы для ранжирования несут в себе наиболее распространенные методы фильтрации.
Виды фильтрации:
Для того чтобы упростить понимание проблемы, разберем системы фильтрации на конкретных примерах.
1. Система фильтрации на Ajax:
Фильтры в данном случае применяются без перезагрузки страницы, и при этом её url адрес не изменяется.
Пример:

Есть ещё вариант такой фильтрации, когда после текущего url адреса добавляется что-то вроде:
#category_id=51&page=1&path=37_51&sort=p.date_added&order=DESC&limit=24&route=product%2Fcategory&min_price=2490 &max_price=8889&attribute_value[10][]=да
Это, скорее всего, система фильтрации на CMS Opencart, тоже Ajax. Всё страницы с хештегом # не индексируются, поэтому рассмотрим данные варианты вместе.
В коде страницы/кеше поисковых систем нет ссылок на страницы фильтрации. В индексе также таких страниц не замечено.
Отсюда следует, что никаких дублей быть не может и поисковая система не тратит свою квоту на индексацию бесполезных страниц по результатам фильтрации вида:
Женские платья / Синие / 44 размера / Mexx / цена от 100 до 500 грн / Распродажа
Очевидно, что на такую страницу не будет трафика, так как это не обусловлено спросом. И нет смысла создавать сотни тысяч таких страниц, это спам и бесполезное использования квоты индексирования.
Но есть и проблема: куда должны вести запросы вида:
- Женские платья Mexx,
- Женские платья из льна,
- Женские платья из Белоруссии.
Для таких запросов нет релевантных страниц, трафик по таким запросам сайт не получит, а это уже проблема. Сайт теряет множество трафика из-за отсутствия релевантных страниц для товарных групп, которые обусловлены спросом.
Плюсы: Нет дубликатов, нет проблем с индексацией.
Минусы: Нет подкатегорий для сбора целевого трафика.
Варианты решения проблем:
В данном случае нам не нужно решать проблемы с индексацией, дублями и мусорными страницами, поэтому тут рекомендаций будет не так много.
1. Необходимое в первую очередь собрать семантическое ядро для всех страниц сайта. Выявить, исходя из спроса, какие подкатегории необходимы для каждой товарной группы.
2. Проконсультироваться с клиентом и программистом, как на данном сайте можно добавить ссылки на странички подкатегорий.
Т.е. необходимо добавить подкатегории, на которые есть или может быть спрос. Естественное, это необходимо сделать без ущерба дизайну и юзабилити.
Примеры реализации:


3. Добавив все необходимые подкатегории, но не стоит забывать про:
- Генерацию корректных чпу url-адресов для подкатегорий;
- Корректную ссылку на подкатегорию в коде страницы, чтобы поисковые системы правильно индексировали новые подкатегории;
- Изменение url-адреса при клике на ссылку;
- Уникальные мета теги и заголовок < h1> для подкатегорий, контент;
- Передачу веса на новые подкатегории, так как на новые страницы всего 1 внутренняя ссылка (из материнской категории). Это очень важно.
2. Фильтрация с добавлением параметра к url-адресу:
Пример:
При применении фильтра, например, «выбор бренда» к url-адресу добавляется параметр
Кроме фильтров по цвету, бренду, материалу могут быть общие фильтры для каждой категории, например:
- По цене,
- От а до я,
- По количеству товаров на странице,
- По популярности,
- По названию,
- Новые,
- Акционные.
Количество таких фильтров может быть очень большим, что, в свою очередь, порождает множество одинаковых по своему содержанию и назначению страниц.
Так как у каждой такой страницы есть уникальный url-адрес, поисковые системы сканируют данные страницы и добавляют многие из них в поисковый индекс. В результате мы получаем сотни тысяч страниц в индексе поисковых систем, но из них лишь 1% является полезным.
Получается, вот такая картина:

Загружено роботом — 860 148.
Страниц в поиске — 116 946.
Полезных и уникальных страниц на сайте ~ 5 000.
Т.е. поисковые системы скачали с сайта почти миллион страниц, а полезных в процентном соотношении там в принципе нет.
Поисковые системы не будут ранжировать высоко сайт, на котором полезное содержание нужно выискивать. У сайта из-за этого проблемы с индексированием, так как квота расходуется на дубликаты и мусорные страницы, а не на полезное содержимое.
Плюсы: есть посадочные страницы для подкатегорий.
Минусы: множество дублей и мусорных страниц, проблемы с индексацией, сайт низко ранжируется.
Решение проблемы:
Данный вид фильтрации гораздо сложнее оптимизировать, так как вариантов решения проблемы очень много.
В первую очередь нам необходимо определиться с целями, а именно:
1. Не допустить попадание в индекс поисковых систем страниц, которые не содержат никакой полезной информации.
2. Обеспечить максимальный охват целевой аудитории.
3. Не допустить сканирование мусорных и дублирующихся страниц. Разумно использовать квоту.
Попробуем пойти по порядку и не запутаться.
1. Необходимо выделить общие параметры для фильтров, по которым мы сможем закрыть данные страницы от индексации при помощи метатега < meta name="robots" content="noindex, follow" />.
*В случае если в url-адресе встречается одновременно 2 параметра, по которым мы закрываем страницы от индексации, мы можем прописать< meta name="robots" content="noindex, nofollow" /> для того, чтобы предотвратить трату квоты на сканирование страниц, запрещенных для индексации. Таким образом, мы решаем сразу 1 и 3 проблему.
Примеры параметров, по которым нужно определить страницы и закрыть их от индексации:
Возьмем всё тот же сайт Lamoda.ua , навскидку я нашёл там следующие параметры:
Это, конечно же, не все параметры, которые нужно закрыть от индексации.
Т.е. нам необходимо закрыть от индексации все страницы, которые содержат в url-адресе следующие фрагменты:
?sizes=
?seasons=
?price=
...
Т.е. мы выбираем все мусорные и бесполезные страницы (которые не принесут нам трафика) и закрываем их от индексации.
Некоторые используют для этих целей файл Robots.txt, но не стоит забывать, что данный файл содержит в себе правила сканирования, а не индексирования. Это не гарантия того, что данные страницы не будут проиндексированы. Данные понятия не стоит путать.
2. Теперь попытаемся увеличить охват целевой аудитории при помощи оптимизации страниц фильтров, которые могут приносить трафик (бренд, материал).
*Собираем семантическое ядро;
*Исходя из семантики, оптимизируем страницы фильтров под запросы;
*Меняем url-адрес на чпу (если не слишком проблематично);
*Реализуем перелинковку для того, чтобы увеличить вес данных страниц.
Таким вот нехитрым образом мы существенно расширим охват целевой аудитории и привлечем дополнительно очень много трафика.
В заключение
При создании/продвижении интернет-магазина очень важно правильно оптимизировать систему фильтрации для того, чтобы сайт ранжировался в соответствии со своей релевантностью, а не находится за топ-100 из-за технических проблем.
Я очень надеюсь, что у вас возникнут вопросы по данной теме на которые я, с удовольствием, отвечу в комментариях.

Подписывайся!




Есть о чем рассказать? Тогда присылайте свои материалы Марине Ибушевой

-
 Mary Smith больше года назадСпасибо за статью! Очень интересно. Но у меня возник такой вопрос. У нас на сайте есть ноутбуки. Хотим внедрить сео фильтры. Оказалось, что пользователи ищут защищенный ноутбук и ноутбук с сим-картой. У нас под эти 2 запроса один и тот же каталог (то есть товары одни и те же). Как быть в таком случае? Если мы сделаем 2 страницы - они же будут дублями?
Mary Smith больше года назадСпасибо за статью! Очень интересно. Но у меня возник такой вопрос. У нас на сайте есть ноутбуки. Хотим внедрить сео фильтры. Оказалось, что пользователи ищут защищенный ноутбук и ноутбук с сим-картой. У нас под эти 2 запроса один и тот же каталог (то есть товары одни и те же). Как быть в таком случае? Если мы сделаем 2 страницы - они же будут дублями? -

 Jek-Ker Zukutoma больше года назадНе знаю, уместен ли будет мой вопрос, но все же хотелось бы прямой пример. Вот мой сайт: arsplus.ru. Фильтры у нас не закрыты для индексации, но если закроем, то потеряем нужные нам страницы. К примеру, в категории видеокарты по фильтру производителя ASUS. Как нам закрыть весь остальной мусор и оставить нужные нам страницы с фильтрами?
Jek-Ker Zukutoma больше года назадНе знаю, уместен ли будет мой вопрос, но все же хотелось бы прямой пример. Вот мой сайт: arsplus.ru. Фильтры у нас не закрыты для индексации, но если закроем, то потеряем нужные нам страницы. К примеру, в категории видеокарты по фильтру производителя ASUS. Как нам закрыть весь остальной мусор и оставить нужные нам страницы с фильтрами?-

 Вариантов реализации достаточно много, я не могу посоветовать Вам идеальный так как нужно общаться с программистом, который работает над сайтом. Обычно в Битриксе проблемнее всего это реализовать.
Вариантов реализации достаточно много, я не могу посоветовать Вам идеальный так как нужно общаться с программистом, который работает над сайтом. Обычно в Битриксе проблемнее всего это реализовать.
Варианты :
1. Простой. Сделать тегами нужные страницы, которые могут собирать трафик, исходя из семантики. Пример - appliances.wikimart.ru/large/refrigerators/
2. Костылем. Сделать глобальную замену нужных url-адресов с фрагментом /filter/ на url, который его н...Вариантов реализации достаточно много, я не могу посоветовать Вам идеальный так как нужно общаться с программистом, который работает над сайтом. Обычно в Битриксе проблемнее всего это реализовать.
Варианты :
1. Простой. Сделать тегами нужные страницы, которые могут собирать трафик, исходя из семантики. Пример - appliances.wikimart.ru/large/refrigerators/
2. Костылем. Сделать глобальную замену нужных url-адресов с фрагментом /filter/ на url, который его не содержит. Остальные закрыть в файле Robots.txt через /filter/. При комбинации из двух и более фильтров /filter/ снова добавляем в url-адрес.
3. Странный. Скрыть все ненужные ссылки через сложный js код(seohide), а нужные пусть индексируются.
4. Сложный. Сделать для определенных категорий фильтров отдельный фрагмент url, по которому их можно закрыть через Robots.txt.
Например для категории arsplus.ru/catalog/kompyuternaya_periferiya/monitory/ есть следующие типы фильтров :
По цене - бесполезные страницы, делаем фрагмент не /filter/, а /price/ и закрываем через Robots.txt
Наличие товара - бесполезные страницы, делаем фрагмент не /filter/, а /nalichie/ и закрываем через Robots.txt
Акции - бесполезные страницы, делаем фрагмент не /filter/, а /akcii/ и закрываем через Robots.txt
Производитель - нужные страницы, делаем фрагмент не /filter/, а /brand/ . Страницы индексируются.
Диагональ - нужные страницы, делаем фрагмент не /filter/, а /diagonal/ . Страницы индексируются.
Разрешение - скорее всего страницы бесполезны, делаем фрагмент не /filter/, а /resolution/ и закрываем через Robots.txt
и т.д.
-
-
 Алексей больше года назадЗдравствуйте.
Алексей больше года назадЗдравствуйте.
Подскажите, пожалуйста, если в созданном интернет магазине страницы с товаром имют несколько линков в зависимости от пути захода на них?
Например сначала находим товар, выбрав категорию , марку авто и тд.
второй вариант - сначала нажав на марку авто, потом выбрав товар для нее
в результате страница одна и та же и одним и тем же товаром, но урлы разные, вот пример:
lab.s1rd.com/car-brand/bmw/m3-sedan/kovriki_v_avto/rezinovie_ko...Здравствуйте.
Подскажите, пожалуйста, если в созданном интернет магазине страницы с товаром имют несколько линков в зависимости от пути захода на них?
Например сначала находим товар, выбрав категорию , марку авто и тд.
второй вариант - сначала нажав на марку авто, потом выбрав товар для нее
в результате страница одна и та же и одним и тем же товаром, но урлы разные, вот пример:
lab.s1rd.com/car-brand/bmw/m3-sedan/kovriki_v_avto/rezinovie_kovriki/rezinovyy-kovrik-va5636
lab.s1rd.com/kovriki_v_avto/rezinovie_kovriki/bmw/m3-sedan/rezinovyy-kovrik-va5636
Что делать для правильной индексации?
Можно как то избегнуть нескольких урлов для одной и той же страницы?-
Здравствуйте.
Для того чтобы не было дубликатов карточек товаров можно использовать rel="canonical", или же 301 редирект.
-
Спасибо за ответ. Еще есть пару вопросов, для прояснения ситуации, для себя лично, так как пытаюсь в этом разобраться и понять в чем суть :)
А что из этого лучше, каноникал или 301?
При использовании rel="canonical" ,
если будут закупать ссылки на одну и ту же страницу по разным линкам (случайно). И будут переходы по разным линкам. То как это отобразится на статистике заходов-переходов? Как это будет видеть аналитика, если переходы на страницу будут по ...Спасибо за ответ. Еще есть пару вопросов, для прояснения ситуации, для себя лично, так как пытаюсь в этом разобраться и понять в чем суть :)
А что из этого лучше, каноникал или 301?
При использовании rel="canonical" ,
если будут закупать ссылки на одну и ту же страницу по разным линкам (случайно). И будут переходы по разным линкам. То как это отобразится на статистике заходов-переходов? Как это будет видеть аналитика, если переходы на страницу будут по разным ссылкам?
Только канонической ссылке будет присваиваться переход или вес?
А можно ли вообще избежать отображения разных урлов на страницу ? (Разработчики говорят, что такое заложено в механике сайта и никак не избежать).
301 редирект поможет решить проблему?
Я правильно понимаю - при использовании 301 для дублирующих ссылок с общими параметрами, просто будет переадресация на правильный урл? И пользователь и поисковик будет видеть только один урл независимо от пути выбора товара?-
1.Что лучше выбрать каноникал или 301 редирект - зависит от ситуации, в Вашем случае я бы выбрал указание канонической страницы.
2.Если переходы будут по разным ссылкам то каким образом система аналитики поймет что это по сути одна страница, но с разными url-адресами?
3.Вес передается через canonical.
4.Конечно можно избежать, нужно править эти моменты. Разработчики лукавят, всё можно поправить, тут дело в желании.
-
-
-
-

 Константин Солодянников больше года назадДелали такой фильтр для Битрикса, marketplace.1c-bitrix.ru/solutions/itlogic.seofilter/.
Константин Солодянников больше года назадДелали такой фильтр для Битрикса, marketplace.1c-bitrix.ru/solutions/itlogic.seofilter/.
Кому актуально, пишите → забросили разработку -
 Vyacheslav Tsurka больше года назадДля 1С-Битрикс мы написали модуль для smart filter(умного фильтра), который решает данную проблему и помогает увеличить охват семантического ядра.
Vyacheslav Tsurka больше года назадДля 1С-Битрикс мы написали модуль для smart filter(умного фильтра), который решает данную проблему и помогает увеличить охват семантического ядра.
marketplace.1c-bitrix.ua/solutions/synpaw.seofilter/ -
 Tsybart больше года назадПодскажите по фильтрам, настроили с урлом такого вида: chehly-iphone-6-kupit?84[0]=Бампера, на сколько плохо будет индексация такого вида и нужно ли ЧПУ (это очень сложно).
Tsybart больше года назадПодскажите по фильтрам, настроили с урлом такого вида: chehly-iphone-6-kupit?84[0]=Бампера, на сколько плохо будет индексация такого вида и нужно ли ЧПУ (это очень сложно). -
 Алексей больше года назадЧто здесь имеется ввиду? /*Реализуем перелинковку для того, чтобы увеличить вес данных страниц./
Алексей больше года назадЧто здесь имеется ввиду? /*Реализуем перелинковку для того, чтобы увеличить вес данных страниц./
Сделал я страницы брендов например. Как должна выглядеть перелинковка?
-
Добрый день, Алексей, спасибо за Ваш вопрос.
Проблема созданных страниц брендов или же фильтров заключается в том что на эти страницы очень мало внутренних ссылок. Чаще всего это вообще одна страница, страница вышестоящей категории.
Вследствие этого данная страница (бренд или фильтр) получает мало веса и плохо ранжируется.
Для того чтобы увеличить количество внутренних ссылок на эту страницу можно сделать следующее, разберем на примере категории "...Добрый день, Алексей, спасибо за Ваш вопрос.
Проблема созданных страниц брендов или же фильтров заключается в том что на эти страницы очень мало внутренних ссылок. Чаще всего это вообще одна страница, страница вышестоящей категории.
Вследствие этого данная страница (бренд или фильтр) получает мало веса и плохо ранжируется.
Для того чтобы увеличить количество внутренних ссылок на эту страницу можно сделать следующее, разберем на примере категории "Телевизоры":
1.Добавить ссылку на страницу бренда Samsung не только на категории "Телевизоры", но и на всех её подкатегориях. Т.е. сделать сквозную ссылку, чтобы страница категории "Телевизоры" и все её подкатегории также ссылались на созданную страницу бренда Samsung.
2.Правильно реализовать хлебные крошки. Чтобы каждая карточка товара телевизоров Samsung имела ссылку на вышестоящую категорию.
Главная -> Телевизоры -> Samsung -> Телевизор Samsung UE22H5600
3.Если это позволяет дизайн или концепция сайта, то можно добавить на каждой странице сайта ссылку в меню на категорию "Телевизоры Samsung".
4.Используя внутренние ссылки со статей, новостей, пресс-релизов или же других категорий товаров.
Вариантов очень много и какой выбрать зависит от сайта, его дизайна и задач, главное это понять существование данной проблемы, а найти оригинальное и работающее решение уже в разы проще.
-
-

-
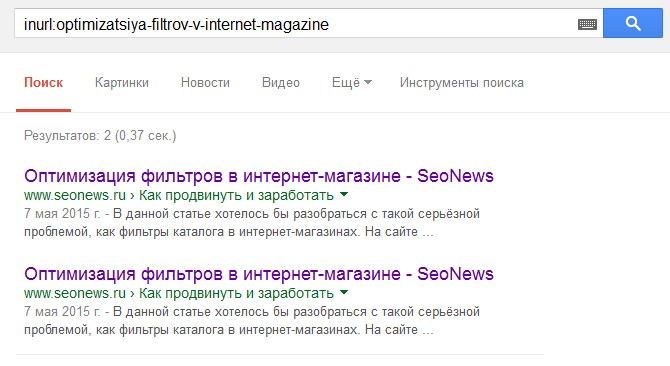
Приведу простой пример:
Введем в поисковую систему запрос :
inurl:optimizatsiya-filtrov-v-internet-magazine
И обнаружим полный дубликат данной статьи в индексе поисковой системы Google.
www.seonews.ru/analytics/optimizatsiya-filtrov-v-internet-magazine/ - оригинал
www.seonews.ru/analytics/optimizatsiya-filtrov-v-internet-magazine/?sphrase_id=1629122 - дубль.
Поэтому на странице www.seonews.ru/analytics/op...Приведу простой пример:
Введем в поисковую систему запрос :
inurl:optimizatsiya-filtrov-v-internet-magazine
И обнаружим полный дубликат данной статьи в индексе поисковой системы Google.
www.seonews.ru/analytics/optimizatsiya-filtrov-v-internet-magazine/ - оригинал
www.seonews.ru/analytics/optimizatsiya-filtrov-v-internet-magazine/?sphrase_id=1629122 - дубль.
Поэтому на странице www.seonews.ru/analytics/optimizatsiya-filtrov-v-internet-magazine/?sphrase_id=1629122 необходимо прописать :
link rel="canonical" href="www.seonews.ru/analytics/optimizatsiya-filtrov-v-internet-magazine/"
Дубль доступен по уникальному url, отдает код 200 и не закрыт от индексирования и сканирования - робот его с легкостью находит и добавляет в индекс.
Как-то так.
-
 Откуда взялась эта переменная в урл из вашего примера? Мне казалось, что ПС может попасть на страницу и добавить её в индекс только по прямой ссылке, в случае фильтрации в магазине как робот узнает об этих урл, он же не может нажимать на кнопки фильтра и генерировать при своем обходе эти урл.
Откуда взялась эта переменная в урл из вашего примера? Мне казалось, что ПС может попасть на страницу и добавить её в индекс только по прямой ссылке, в случае фильтрации в магазине как робот узнает об этих урл, он же не может нажимать на кнопки фильтра и генерировать при своем обходе эти урл.-
Генерит Bitrix. Нашёл даже ветку на форуме о том как исправить данную проблему dev.1c-bitrix.ru/community/forums/forum6/topic30053/.
Прямая ссылка - не единственна возможность индексации страницы.
В большинстве систем фильтрации - элементы фильтров являются обычными ссылками. Никаких проблем с индексацией у поисковых систем не возникнет в данном случае.
-
-
-
-

 Дмитрий Смирнов больше года назадВладислав, ай как грубо. Зачем вводить читателей в заблуждение? Вы говорите, ссылась на данные Я. Веб мастера «Загружено роботом — 860 148» «Страниц в поиске — 116 946», но если страницы закрыты от индексации в роботс Я будет показывать «860 148» даже если они закрыты в момент создания страницы как таковой и никогда не были в индексе Я
Дмитрий Смирнов больше года назадВладислав, ай как грубо. Зачем вводить читателей в заблуждение? Вы говорите, ссылась на данные Я. Веб мастера «Загружено роботом — 860 148» «Страниц в поиске — 116 946», но если страницы закрыты от индексации в роботс Я будет показывать «860 148» даже если они закрыты в момент создания страницы как таковой и никогда не были в индексе Я-
Добрый день, Дмитрий, спасибо за Ваш вопрос.
Данный скриншот был размещен с целью визуализировать для читателей количество страниц, которые обходит робот, индексирует и исключает.Чтобы был понятен объем проделанной работы краулером поисковой системы Яндекс для того чтобы проиндексировать всего-то 5000 страниц ему приходится сканировать миллион мусорных страниц.
Это серьёзная проблема с индексацией, её необходимо решать.
Надеюсь я ответил на Ваш вопрос.-
 К примеру у нас на нем всего 10 страниц, в «Загружено роботом — 10» в «Страниц в поиске — 10»
К примеру у нас на нем всего 10 страниц, в «Загружено роботом — 10» в «Страниц в поиске — 10»
Мы добавили на сайт еще 100 страниц при этом наплодили 50 фильтров, сразу до обхода пауком, закрыли 50 фильтров в роботсе
Итого, в веб мастере будет «Загружено роботом — 160» «Страниц в поиске — 110»-
Да, так и есть, только с одной поправочкой, загруженных страниц будет намного больше чем 160. Так как есть ещё комбинации различных фильтров, поэтому загруженных страниц будет намного больше.
Главное чтобы сканировались и индексировались поисковыми системами лишь важные страницы, именно об этом я хотел сказать в данной статье.
-
-
-
-

 Илья Фомичев больше года назадА еще можно использовать раздел Параметры URL Гугл вебмастера для Гугла и прописать clean param в роботсе для Яндекса
Илья Фомичев больше года назадА еще можно использовать раздел Параметры URL Гугл вебмастера для Гугла и прописать clean param в роботсе для Яндекса -
-
Добрый день, Виктор. Спасибо за Ваш вопрос.
К сожалению, у большинства популярных CMS такая проблема с фильтрами имеет место быть. В оправдание разработчиков CMS могу сказать что это не их задача оптимизировать сайт для поисковых систем. Всё что они могут дать это :
Сделать по умолчанию фильтрацию на ajax или закрыть все страницы фильтров и сортировок от сканирования в файле robots.txt.
Я затрудняюсь ответить какие CMS по умолчанию решают данную проблему...Добрый день, Виктор. Спасибо за Ваш вопрос.
К сожалению, у большинства популярных CMS такая проблема с фильтрами имеет место быть. В оправдание разработчиков CMS могу сказать что это не их задача оптимизировать сайт для поисковых систем. Всё что они могут дать это :
Сделать по умолчанию фильтрацию на ajax или закрыть все страницы фильтров и сортировок от сканирования в файле robots.txt.
Я затрудняюсь ответить какие CMS по умолчанию решают данную проблему одним или другим методом так как в работе ещё не встречал таких сайтов. Везде что-то необходимо было переделывать.
При работе с каждым движком необходимо обращать вниманию на данную проблему и искать оптимальные пути решения.
-

 Урган Фрост больше года назадВладислав, а как ПС относятся к такому явлению, что товар на Общем разделе есть, а также часть товаров есть в его подразделах? Т.е. раздел Фрукты содержит Яблоко красное, Яблоко зеленое .. На подразделе Яблоки будут опять же Яблоко красное, Яблоко зеленое .. нет ли в этом проблемы? Естественно, при условии что каждое Яблоко (самая карточка товара) доступна только по одному УРЛу.
Урган Фрост больше года назадВладислав, а как ПС относятся к такому явлению, что товар на Общем разделе есть, а также часть товаров есть в его подразделах? Т.е. раздел Фрукты содержит Яблоко красное, Яблоко зеленое .. На подразделе Яблоки будут опять же Яблоко красное, Яблоко зеленое .. нет ли в этом проблемы? Естественно, при условии что каждое Яблоко (самая карточка товара) доступна только по одному УРЛу.
И еще вопрос с цепочкой в УРЛе. Думается, ПС должна понимать, что товары относятся к определе...Владислав, а как ПС относятся к такому явлению, что товар на Общем разделе есть, а также часть товаров есть в его подразделах? Т.е. раздел Фрукты содержит Яблоко красное, Яблоко зеленое .. На подразделе Яблоки будут опять же Яблоко красное, Яблоко зеленое .. нет ли в этом проблемы? Естественно, при условии что каждое Яблоко (самая карточка товара) доступна только по одному УРЛу.
И еще вопрос с цепочкой в УРЛе. Думается, ПС должна понимать, что товары относятся к определенной группе не только из-за листинга на странице, но и из-за включения в УРЛе основного раздела, так ли это?-
1.Конечно же не будет никаких проблем. Нет ничего страшного в том что, например, LED-телевизор SAMSUNG UE32H5500AK находится в категориях :
- Телевизоры;
- Телевизоры Samsung;
- Led телевизоры;
- Телевизоры с диагональю 32" (81 см).
Как вы и сказали, главное чтобы у карточки товара был один url адрес.
2.Это так, но не стоит обращать на это особого внимания. Нет ничего страшного если товар не будет содержать в url...1.Конечно же не будет никаких проблем. Нет ничего страшного в том что, например, LED-телевизор SAMSUNG UE32H5500AK находится в категориях :
- Телевизоры;
- Телевизоры Samsung;
- Led телевизоры;
- Телевизоры с диагональю 32" (81 см).
Как вы и сказали, главное чтобы у карточки товара был один url адрес.
2.Это так, но не стоит обращать на это особого внимания. Нет ничего страшного если товар не будет содержать в url адресе раздела, в котором находится товар.
У многих CMS url товара выглядит вот так :
site.ua/product1421/
Это даже хорошо, не будет дублей карточки товара.
У многих интернет магазинов есть следующая проблема - карточка товара одновременно находится по нескольким url, пример :
site.ua/televizory/UE32H5500AK/
site.ua/televizory/samsung/UE32H5500AK/
site.ua/televizory/32/UE32H5500AK/
Это нужно исправлять.
-
-
Marketologov больше года назадСтранно что не описали такой атрибут как link rel="canonical"
Активно используется для скрытия дублей и действует лучше robots.txt и meta name="robots"
Таже самая Ламода это использует-
Данный атрибут тоже подходит для этих целей, если всё правильно реализовать. Т.е. написать со всех ненужных страниц фильтров canonical на основные страницы.
В случае если интернет магазин достаточно большой то выполнить это правильно достаточно проблематично и трудозатратно. Потому что многие из страниц фильтров необходимы для сбора трафика, из-за этого очень трудоемко отделить мух и котлет.
Поэтому в статье был указан более простой вариант с ограничением индексации...Данный атрибут тоже подходит для этих целей, если всё правильно реализовать. Т.е. написать со всех ненужных страниц фильтров canonical на основные страницы.
В случае если интернет магазин достаточно большой то выполнить это правильно достаточно проблематично и трудозатратно. Потому что многие из страниц фильтров необходимы для сбора трафика, из-за этого очень трудоемко отделить мух и котлет.
Поэтому в статье был указан более простой вариант с ограничением индексации данных страниц.
На самом деле вариантов исправления данной проблемы достаточно много, если описывать каждый из них, статья получилась бы такого размера, что её никто не стал бы читать.
-
-
 Marketologov больше года назад"Не допустить сканирование мусорных и дублирующихся страниц. Разумно использовать квоту."
Marketologov больше года назад"Не допустить сканирование мусорных и дублирующихся страниц. Разумно использовать квоту."
Вот о квоте можно было бы поподробней?
Что это ха квота и какова она?
Есть ли оф. сведения от ПС или реальные кейсы где выявляли эти квоты?-
О квоте написано в справке поисковой системы Google - support.google.com/webmasters/answer/182072?hl=ru
Робот Googlebot применяет алгоритмический процесс: компьютерные программы определяют сайты, которые нужно сканировать, а также частоту сканирования и количество извлекаемых страниц на каждом сайте. (c)
Квота, грубо говоря, это то количество страниц, которое GoogleBot считает нужным обходить в течении определенного периода. Конечно же, я не знаю как точно ра...О квоте написано в справке поисковой системы Google - support.google.com/webmasters/answer/182072?hl=ru
Робот Googlebot применяет алгоритмический процесс: компьютерные программы определяют сайты, которые нужно сканировать, а также частоту сканирования и количество извлекаемых страниц на каждом сайте. (c)
Квота, грубо говоря, это то количество страниц, которое GoogleBot считает нужным обходить в течении определенного периода. Конечно же, я не знаю как точно рассчитывается квота, я могу лишь предполагать. По моему мнению влияют следующие факторы :
- Вес документов на сайте, имеется в виду количество килобайт;
- Структура сайта;
- Частота обновления контента;
- Частота добавления новых страниц;
- Количество "мусорных" страниц;
- Авторитетность ресурса;
- И многое другое.
Список можно продолжать ещё на пунктов 20)
Конечно же, поисковая система не будет часто индексировать и выкачивать много страниц сайтов низкого качества, которые не обновляются годами, содержат только копипаст и продают ссылки.Лучше ресурсы потратить на индексацию частообновляемых сайтов с полезным контентом.
-
-

 Андрей Андрей больше года назадДа, вы пишете что некоторые закрывают их в robots, типо это не совсем правильно, но не сказали как правильно по вашему сделать закрытие. И можно пример.
Андрей Андрей больше года назадДа, вы пишете что некоторые закрывают их в robots, типо это не совсем правильно, но не сказали как правильно по вашему сделать закрытие. И можно пример.
Спасиб!)-
По моему мнению правильно закрывать такие страницы через мета тег meta name="robots" content="noindex, follow" или же nofollow, зависит от ситуации.
Более подробно об этом вы сможете прочитать в справке support.google.com/webmasters/answer/93710?hl..
Пример реализации:
comfy.ua/telephone-smartfon/smartfon.html?smar..
Спасибо за вопрос.-
Владислав Наумов больше года назадcomfy.ua/telephone-smartfon/smartfon.html?smart_razr=Quad+HD+2560x1440
support.google.com/webmasters/answer/93710?hl=ru
Поправил ссылки.
-
-
-
Стас больше года назадДоброе утро! Читаю ваши статьи - все очень толково! Продолжайте, пожалуйста! Не могли бы вы привести примера кода в роботс.txt с закрытием такие страниц как:
?sizes=
?seasons=
?price=
Т.е показать готовый пример robots.txt-
User-agent: *
Disallow: *?seasons=*
Disallow: *?sizes=*
Disallow: *?price=*
Host: site.ua
Sitemap: site.ua/sitemap.xml-
Владислав, правило в роботсе не может начинаться не с чего кроме слеша. следовательно правильно будет Disallow: /*?seasons=* да и звезду в конце ставить не обязательно, т.е. Disallow: /*?seasons=
-
Спасибо за замечание.
Подскажите, пожалуйста, где указано что обязательно необходимо указывать / перед каждым правилом.
По поводу звездочки - согласен. Это что-то вроде перестраховки :)
В любом случае данный файл Robots.txt будет правильно восприниматься поисковыми системами и при его проверке не будет никаких ошибок.
-
-
-